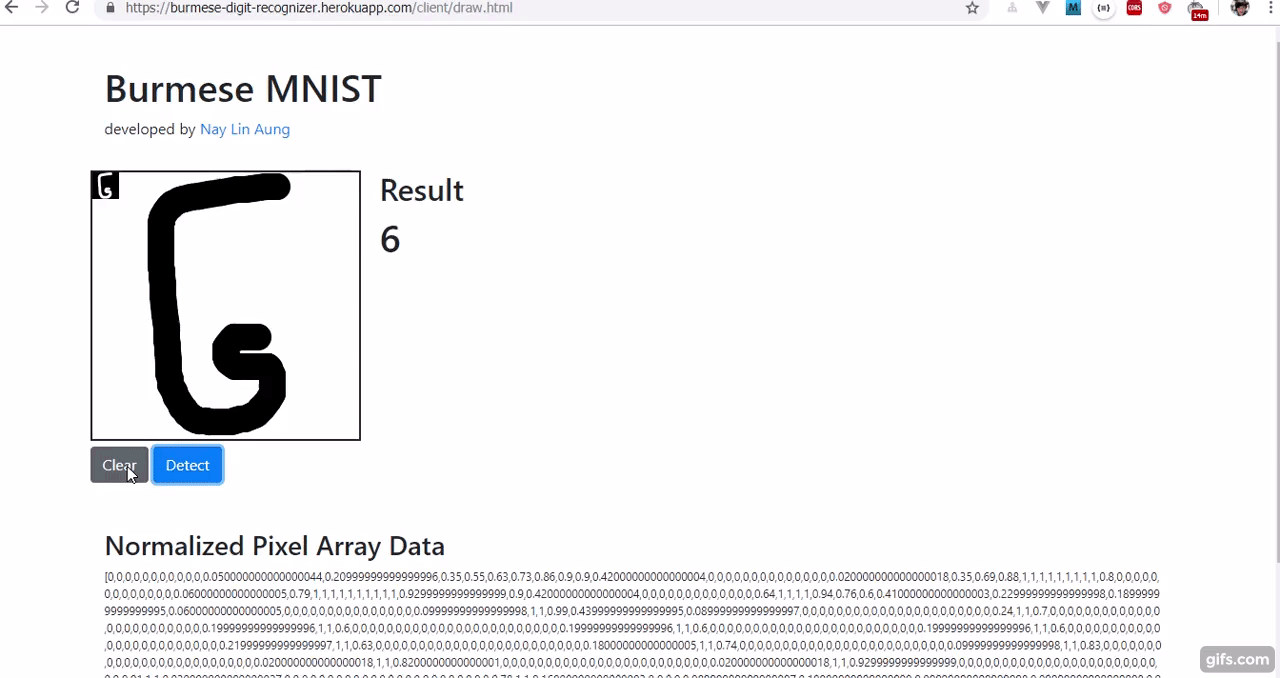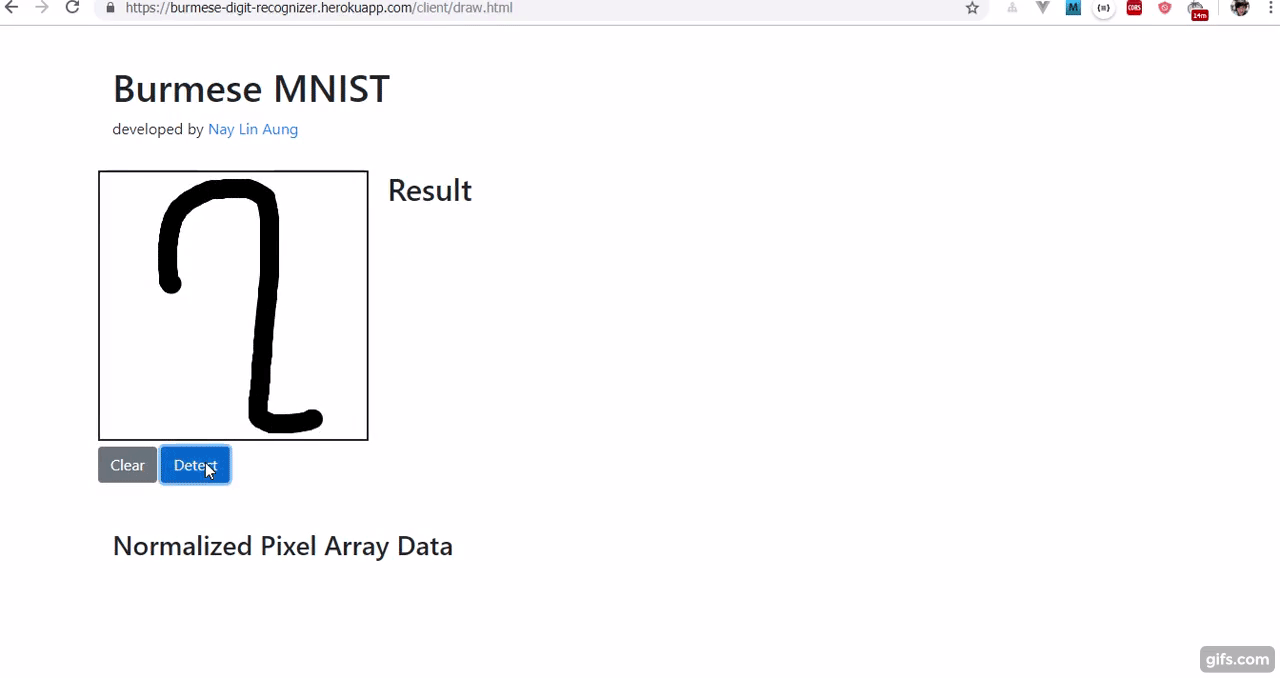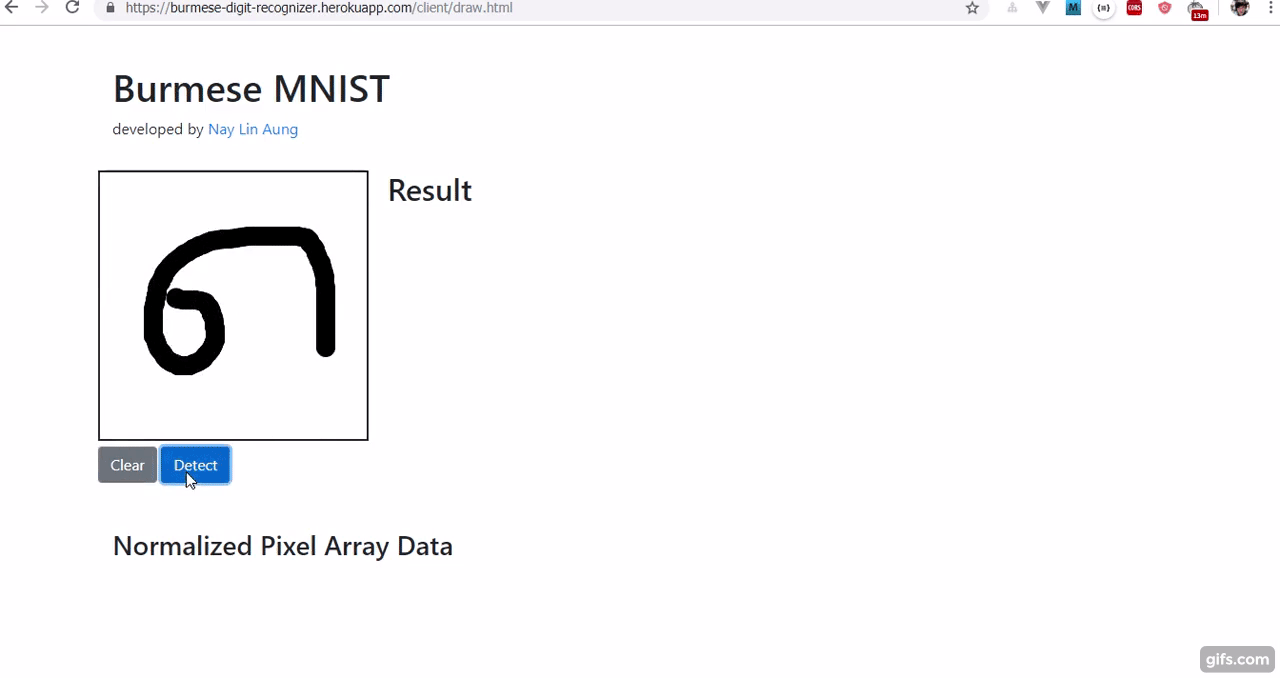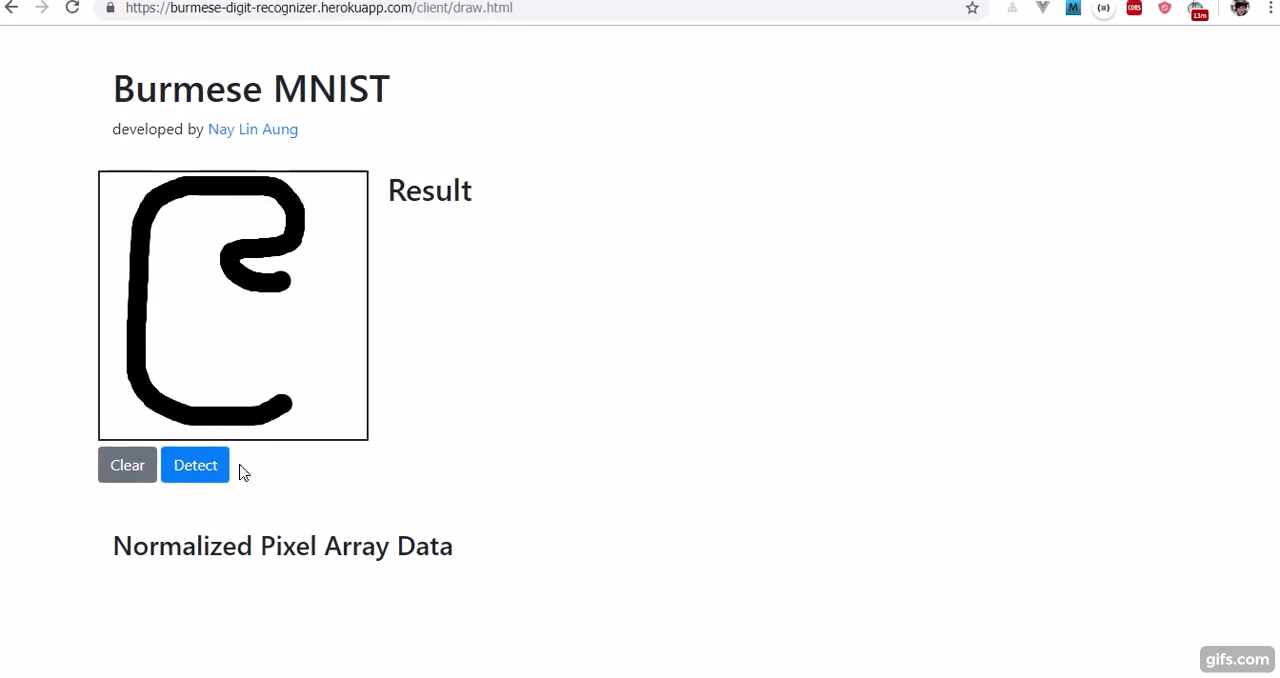

Burmese Digit Recognizer using one-hidden layer Neural Network based on BHDD Burmese Handwritten Digit Dataset.

Machine Learning နည်းပညာကို အသုံးပြုပြီး develop လုပ်ထားတဲ့ Burmese Handwritten Digit Recognizer လေးပါ။ Synaptic.js ကို အသုံးပြုပြီး one-hidden layer Neural Network တည်ဆောက်ပြီး ရေးသားထားတာပါ။ Dataset အနေနဲ့ BHDD dataset ကို အသုံးပြုထားပါတယ်။
Project ရဲ့ trained_models folder ထဲမှာ train ပြီးသား model ကို json file format နဲ့ သိမ်းပေးထားပါတယ်။ Node.js နဲ့ စမ်းခြင်တယ်ဆိုရင် model file ကို fs နဲ့ read လုပ်ပြီး စမ်းကြည့်လို့ ရပါတယ်။ Sample အနေနဲ့ Predict.js ဆိုပြီး ရေးပေးထားတာ ရှိပါတယ်။
ဒါပေ့သိ burmese digit အတွက် Predict ကတော့ Burmese Handwritten Digit Json Dataset ကို မထည့်ပေးလိုက်တဲ့အတွက် စမ်းလို့ ရမှာ မဟုတ်ပါဘူး။ ကိုယ်တိုင် Json Dataset ပြန်ထုတ်နိုင်ဖို့ Data Pre-processing အပိုင်းကို လေ့လာပြီး လုပ်ကြည့်လို့ရပါတယ်။
အကယ်လို့ browser ထဲမှာ canvas နဲ့ ရေးပြီး စမ်းကြည့်ခြင်ရင်တော့ client folder ထဲမှာ burmese_digit_draw.html နဲ့ english_digit_draw.html ဆိုပြီး ရေးပေးထားပါတယ်။
သက်ဆိုင်ရာ file ကို browser တွင် တိုက်ရိုက်ဖွင့်ပြီး စမ်းကြည့်လို့ ရပါတယ်။
သတိထားစရာ နှစ်ချက်ရှိပါတယ်။
- ပထမအချက်က ဂဏန်း ၁ လုံးဘဲ ရေးလို့ ရပါသေးတယ်။ ၁ ဆို ၁၊ ၂ ဆို ၂ တလုံးတည်းပါ။
- နောက်တစ်ခုက စမ်းတဲ့အခါ canvas ရဲ့ အလယ်တည့်တည့်မှာ ဂဏန်းကို ခပ်ကြီးကြီးနဲ့ အပြည့်ရေးပေးဖို့ လိုပါတယ်။
တကယ် train ကြည့်တော့ ရလာတဲ့ model က test data နဲ့တော့ အကုန်နီးပါးမှန်ပြီး error rate အတော်လေးနည်းတယ် ဆိုပေမယ့် တကယ်တမ်း canvas ပေါ်မှာ ရေးပြီး စမ်းကြည့်တဲ့အခါ အဆင်မပြေတာလေးတွေတွေ့လာရပါတယ်။ အဓိကပြဿနာက canvas ပေါ်က image pre-processing လုပ်တာ လိုအပ်ချက်ရှိနေသေးတာကြောင့်လို့ ထင်ပါတယ်။
အဓိက Programming language အနေနဲ့ကတော့ Javascript ကိုဘဲ ရွေးချယ်ခဲ့ပါတယ်။ ကိုယ်က web developer ဖြစ်တဲ့အလျောက် ကိုယ်နဲ့ရင်းနှီးတဲ့ language တစ်ခုကို ရွေးလိုက်တဲ့ သဘောပါဘဲ။
Javascript ထဲကမှ ကျွန်တော် အတော်လေးသဘောကျတဲ့ Synaptic.js ဆိုတဲ့ library လေးကို ရွေးချယ်ခဲ့ပါတယ်။ ။ ပြီးပြည့်စုံတဲ့ tensorflow.js လိုမျိုး ရှိရက်သားနဲ့ ဘာကြောင့် အဲဒီ library ကို ရွေးခဲ့တာလဲပေါ့။
Synaptic.js က တကယ့်ကို tiny library လေးပါ။ code files စုစုပေါင်း 12 ခုဘဲ ပါပါတယ်။ Pre-defined architectures တွေဖယ်လိုက်ရင် 8 files ဘဲ ကျန်ပါတော့တယ်။ အဲဒီထဲကမှ အကြီးဆုံး file က code line ပေါင်း ၆၀၀ လောက်ဘဲ ရှိတာပါ။
အဲ့တော့ source code တွေက အတော်လေး accessible , readable ဖြစ်ပါတယ်။ သူနောက်ကွယ်မှာ ဘယ်လိုရေးထားလဲဆိုတာ သိဖို့ source code တွေကို ဝင်ဖတ်လို့ရတာဟာ လေ့လာနေဆဲသူတွေအတွက် အတော်လေး တာသွားစေတဲ့အချက်ပါ။
“library က method တစ်ခုကို လှမ်းခေါ်လိုက်တာ မည့်သို့မည်ပုံ ဖြစ်သွားသည်မသိ၊ အလိုလို အကုန်ဖြစ်သွားတယ်”
ဆိုတာမျိုး မကြုံရတော့ဘူးပေါ့။
ဒါက ML လုပ်တဲ့သူတိုင်း မဖြစ်မနေလုပ်ရတဲ့ အဆင့်တစ်ခုပါဘဲ။ BHDD မူရင်းကတော့ Dataset ကို python pickle file လေးနဲ့ distribute လုပ်ပေးထားတာ တွေ့ရတယ်။ ဒါမယ့် ကိုယ်ကတော့ အဲ့ဒါကို Yann Lecun ရဲ့ English MNIST format အတိုင်း idx format ကို ပြန်ပြောင်းလိုက်ပါတယ်။ Byte arragement တွေကအစ အားလုံးအတူတူဖြစ်အောင် ပြင်လိုက်ပါတယ်။ အခြား Language တွေရဲ့ Dataset loader အားလုံးနီးပါးက idx format ရဲ့ byte arrangement အတိုင်း data ဖတ်ကြတာဆိုတော့ နောက်စမ်းမယ့်သူတွေလည်း အဆင်ပြေသွားအောင်လို့ပါ။
ပြီးနောက်မှာ Synaptic.js အတွက် သီးသန့် Json format ကို MNIST_DL script သုံးပြီး ပြန်ပြောင်းလိုက်ပါတယ်။
(idx format ပြောင်းပြီးသား dataset ကိုရော၊ Json format နဲ့ dataset ကိုရော ကျွန်တော် repo ထဲမှာ မထည့်ထားပါဘူး။ format ပြောင်းဖို့ ရေးထားတဲ့ python script ကိုတော့ ထည့်ပေးလိုက်ပါတယ်။ အဓိက Dataset ကို တဆင့်ပြန်ဖြန့်သလို ဖြစ်သွားမှာ စိုးရိမ်လို့ပါ။)
Network ကတော့ 100 neurons ပါတဲ့ one-hidden layer နဲ့ဘဲ ဆောက်လိုက်ပါတယ်။ 200 neurons နဲ့ တည်ဆောက်ကြည့်သေးပေမယ့် တကယ် train ကြည့်တဲ့အခါ ထင်သလောက် ရလဒ်မကောင်းဘဲ learning rate က iteration တစ်ခုနဲ့တစ်ခုကြား လိုတာထက်ပိုပြီး အရမ်းကြာနေတာကို တွေ့ရပါတယ်။ Activation function ကတော့ Logistic (Sigmoid) သုံးထားပါတယ်။ Output layer အတွက်တော့ Softmax activation ကို library မှာ မပါလာလို့ ကိုယ်ဘာကိုဘဲ ဖြည့်ရေးလိုက်ပါတယ်။ Loss function ကတော့ အားလုံးသိပြီးသား Cross entropy ဘဲ သုံးထားပါတယ်။
Training algorithm ကတော့ Synaptic.js ရဲ့ ကျောရိုးအနေနဲ့ ပါလာတဲ့ Google developer Derek Monner ရဲ့ LSTM ကို အခြေခံထားတဲ့ architecture free LSTM-g ဆိုတဲ့ algorithm ကိုဘဲ အသုံးပြုလိုက်ပါတယ်။
နောက်ဆုံးအဆင့် train တာကိုတော့ AWS EC2 ကို c4.8xlarge type နဲ့ instance တစ်ခုဆောက်ပြီး run ပါတယ်။ Node server နဲ့ဘဲ train တာပါ။ Instance ဖိုးတော့ USD 25 လောက် ကုန်ကျမှု ရှိပါတယ်။
Training data 40000 နဲ့ iteration ပေါင်း ၃၀၀ အကျော်လောက် train အပြီးမှာတော့ error rate 0.01 လောက်ရလာလို့ train တာ break လိုက်ပါတယ်။
ဒါကတော့ အပျော်ရဆုံး အပိုင်းပါဘဲ (Pun intended) ။ ဒီအကြောင်း အသေးစိတ်ရေးမယ်ဆိုရင် article တစ်ပုဒ်စာ ထွက်သွားနိုင်ပါတယ်။
Web development လုပ်တာကြာပြီဆိုပေမယ့် html5 canvas ကိုတော့ တခါမှ မစမ်းဖူးတာ အမှန်ပါ။ ခုကျတော့ Canvas ပေါ်မှာ ဆွဲလိုက်တဲ့ Digit ကို model ထဲ ထည့်ပြီး classify လုပ်ရမှာဆိုတော့ Canvas အကြောင်း အသေးစိတ် သိဖို့က လိုလာတယ်။
ပထမဆုံး scaling လုပ်ရပါတယ်။ Canvas က ပေးထားတာ 280 x 280 ဆိုပေမယ့် trained image size 28 x 28 ကို ပြန်ချုံရပါတယ်။
နောက်တစ်ခုအနေနဲ့ MNIST dataset ထဲက image တွေက 20 pixles ထဲမှာဘဲ digit ကို ဝင်အောင်ဆွဲထားပြီး 4 pixels ကို all-around corners အနေနဲ့ထား ထားပါတယ်။ အဲ့အတွက် center image scaling ထပ်လုပ်ရပါတယ်။ နောက်မှာတော့ pixels point တွေကို 0 to 1 range အကြားရဖို့ normalize ပြန်လုပ်ရပါတယ်။ အဲ့အတွက် grayscale image တစ်ခုအဖြစ် အရင်ပြန်ပြောင်းရပြန်တယ်။
ကံကောင်းထောက်မစွာ online က code reference လေးတစ်ခုရခဲ့ပြီး ကိုယ့်လိုအပ်ချက်အတိုင်း အသေးစိတ် လိုက်ပြင်ပြီးတဲ့ နောက်မှာတော့ အဆင်ပြေတဲ့ Canvas Input နဲ့ Image pixel array data လေး ရလာပါတယ်။
အဲ့မှာ တစ်ခုတွေ့တာက English MNIST dataset နဲ့ train ထားတဲ့ model မှာတော့ image တွေကို scaling လုပ်ပြီးမှသာ မှန်အောင် predict လုပ်ပေးနိုင်ပါတယ်။ BHDD မှာတော့ canvas က image တွေကို 4 pixels corners scaling လုပ်လိုက်ရင် prediction က အနည်းငယ်အမှားများတာ တွေ့ရပါတယ်။ ဒါကြောင့် Burmese version မှာတော့ corner scaling ကို 1 pixel ဘဲထား ထားပါတယ်။
ဒါက ကျွန်တော့် တနေရာရာမှာ လိုအပ်ချက်ရှိသွားလို့လည်း ဖြစ်နိုင်ပါတယ်။
နောက်ဆုံးအနေနဲ့ Canvas လေးနဲ့ မြန်မာဂဏန်းအက္ခရာတွေကို ရေးသားနိုင်ပြီး ဘယ်နံပါတ်လဲဆိုတာ (မမှန်တမှန်။ အဓိက canvas image proprocessing ကြောင့်ပါ ) ခန့်မှန်းပေးနိုင်တဲ့ Recognizer လေးတစ်ခု ရလာပါပြီ။
အလောတကြီး အားတဲ့အချိန်လေးမှာ ရေးထားရတာဆိုတော့ နောက်ကွယ်က js code က သပ်ရပ်မှုအား နည်းပါသေးတယ်။
နောက်ထပ် network အသွင်ကွဲ ပုံစံမျိုးတွေနဲ့ စမ်းပြီး ရလာတဲ့ result တွေကိုလည်း တတ်နိုင်သလောက် ဒီ repo မှာဘဲ ဆက်လက် တင်ပေးသွားပါဦးမယ်
- Canvas on mobile browsers (done)
- Responsive Canvas
- Image pre-processing on canvas
- Train data with CNN
- Tint Naing Win (Canvas on mobile browsers)
 https://github.com/stevenay/burmese_digit_recognizer_with_nn
https://github.com/stevenay/burmese_digit_recognizer_with_nn












